
{kind=link}
Alright folks, let me walk you through how I tackled predicting the Premier League relegation zone this year. It was a fun little project, and I learned a ton along the way.
Getting Started: Data, Data, Data
First things first, I needed data. I scraped historical Premier League data from a couple of sports stats websites. Think of things like: goals scored, goals conceded, wins, losses, points, and even stuff like average possession. I made sure to grab data going back a good few seasons to get a decent historical perspective. Wrangling that data into a usable format in Pandas was probably the most tedious part, to be honest.
Feature Engineering: Making the Data Sing
Raw data is boring. I started messing around with creating some features. For example, instead of just “goals scored,” I calculated “goal difference” (goals scored minus goals conceded). I also whipped up a “points per game” metric. Played around with rolling averages too – you know, average goals scored over the last 5 games, that kind of thing. This step is where you really start to get a feel for what might actually be predictive.
Choosing a Model: Keep it Simple, Stupid
I’m no machine learning wizard, so I went with a relatively simple model: a Logistic Regression. It’s easy to understand and interpret. I split my data into training and testing sets, and then fed the training data into the model. The goal was to predict whether a team would be relegated (1) or not (0).
Training and Tuning: Finding the Sweet Spot
This part involved a lot of trial and error. I played around with the regularization parameter in the Logistic Regression to avoid overfitting. Basically, I wanted the model to generalize well to new data, not just memorize the training data. Cross-validation was my friend here – it helped me estimate how well the model would perform on unseen data.
Making Predictions: The Moment of Truth
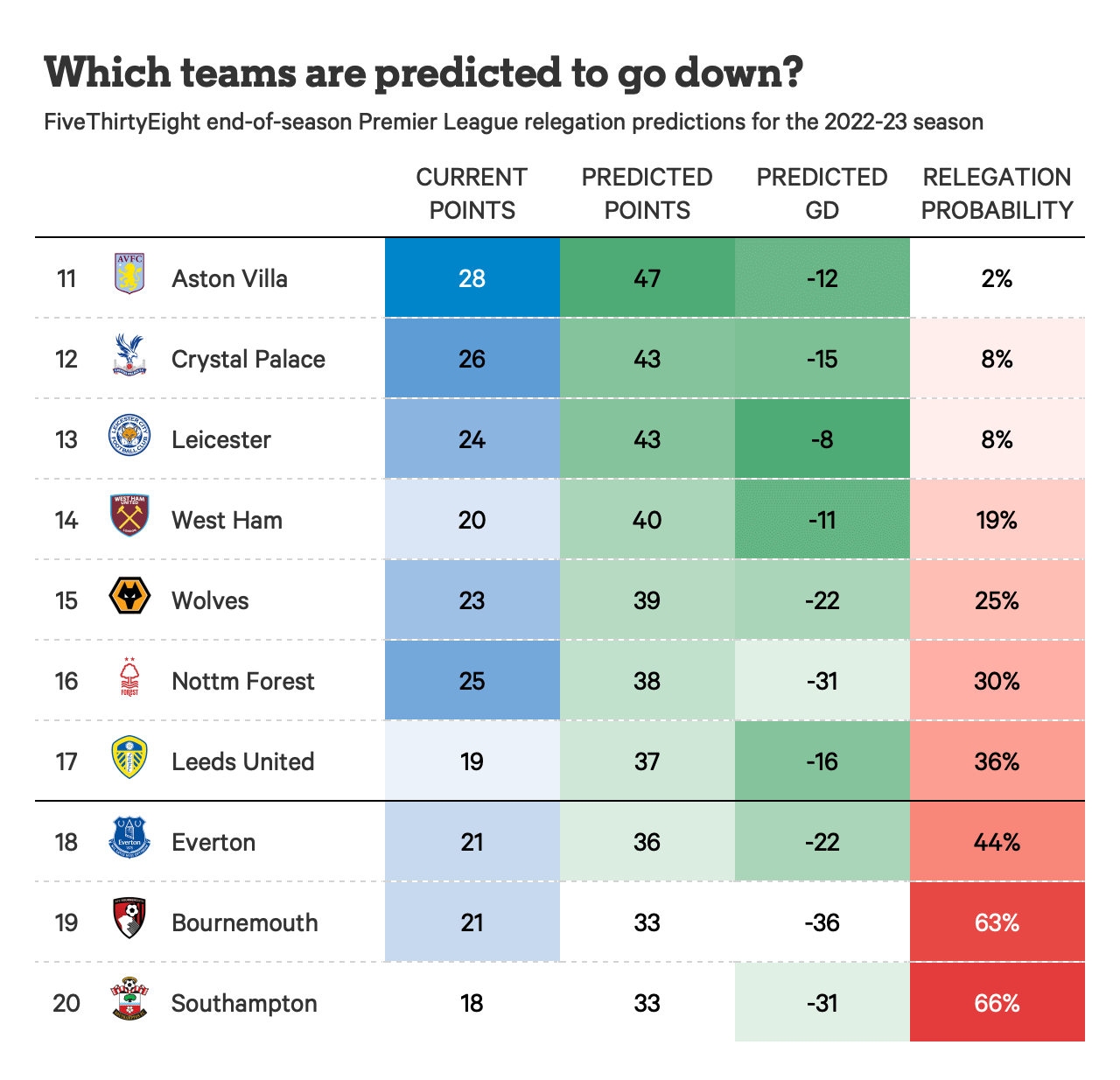
Once I was happy with the model, I fed it the current season’s data (up to a certain point, of course, to simulate making predictions mid-season). The model spat out probabilities – the probability that each team would be relegated. I sorted the teams by relegation probability and, boom, there were my predicted relegation candidates.

Analyzing the Results: Reality Bites
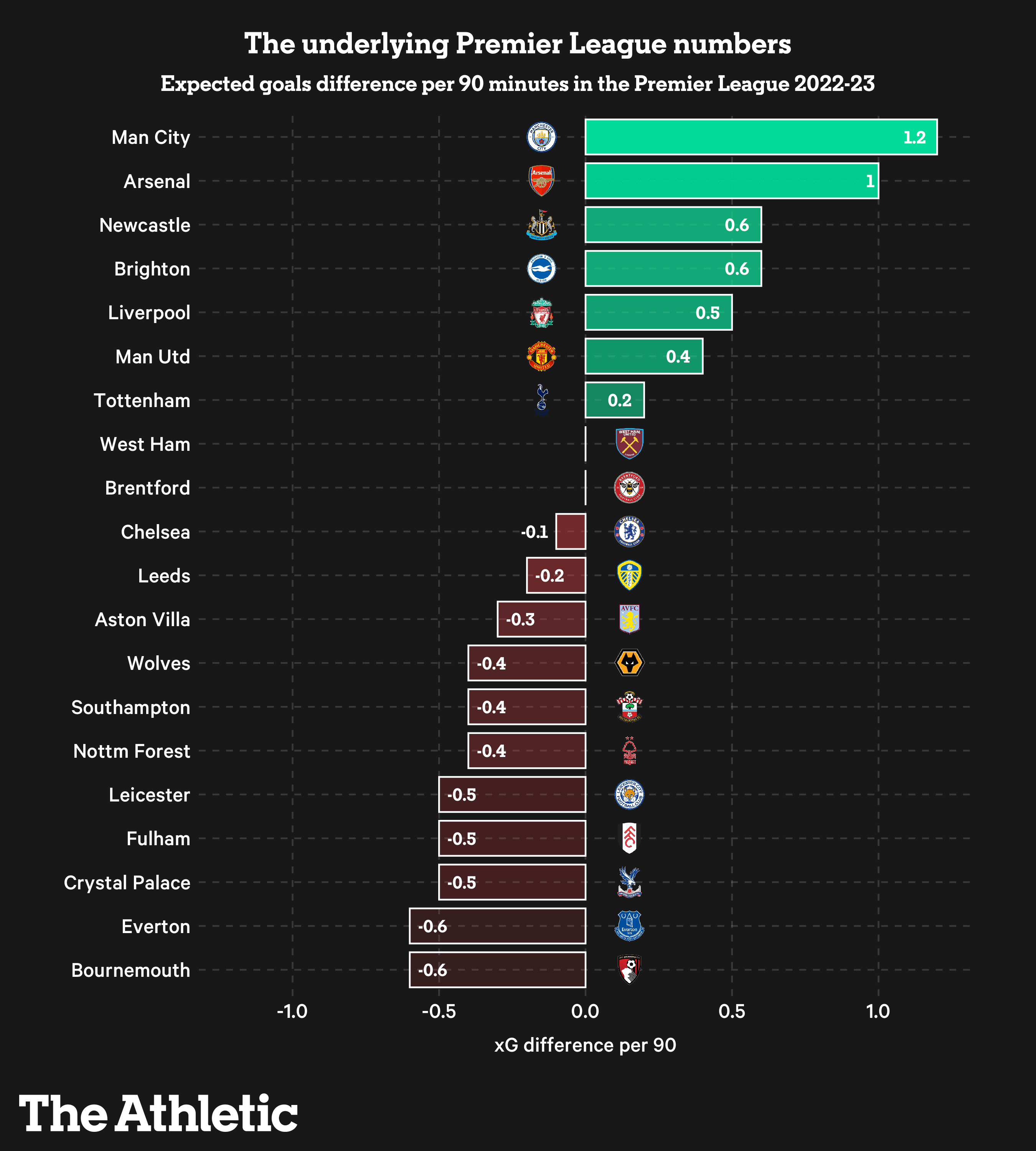
Did I get it 100% right? Of course not! Football is chaotic. But it was interesting to see which features the model considered most important. Goal difference and points per game were big ones, unsurprisingly. But some of the rolling average features also popped up as significant.
What I Learned: It’s All About the Process
This wasn’t about getting the “right” answer. It was about going through the process of collecting data, cleaning it, building a model, and seeing what insights you can extract. Plus, it gave me some extra talking points for pub conversations about football!
Next Steps: More Data, More Models

If I were to do this again, I’d probably try incorporating more data. Maybe things like player injuries, team form over longer periods, or even betting odds. And I’d experiment with more complex models, like a Random Forest or Gradient Boosting machine. But for a quick weekend project, I was pretty happy with how it turned out.